
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 컴포넌튼
- 0.75px border
- ZOOM
- TS
- TypeScript
- Websocket
- entity
- 1px border
- Strict
- github
- es6
- Props
- 0.25px border
- 문서번호
- literal
- jwt
- &연산
- 으
- 당근마켓
- angular
- font-size
- 클론코딩
- 10px
- 서버리스 #
- 전역변수
- ES5
- 데이터베이스 #try #이중
- npm
- 타입스크립트
- 0.5px border
Archives
- Today
- Total
복잡한뇌구조마냥
[DB] Cache Stampede ( 캐시 스탬피드 ) 본문
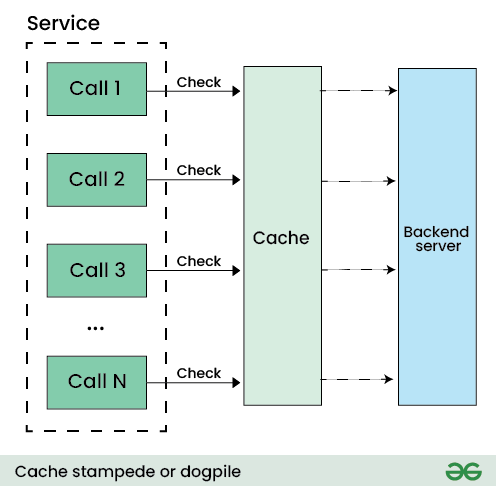
대규모 트래픽 환경에서 캐시를 사용하다 보면, 특정 시점에 DB로 요청이 한꺼번에 몰리는 현상이 발생할 수 있다.
이를 Cache Stampede(캐시 스탬피드) 라고 부른다.
간단히 말하면,
캐시가 비는 순간, 모든 요청이 동시에 DB로 몰려가는 문제
이다.
🧩 캐시 스탬피드는 언제 발생할까?
가장 대표적인 상황은 다음과 같다.
1️⃣ 캐시 만료(TTL Expire) 시점
- 인기 데이터(메인 페이지, 인기 게시글, 랭킹 등)
- 캐시 TTL이 만료되는 순간
- 다수의 요청이 동시에 유입
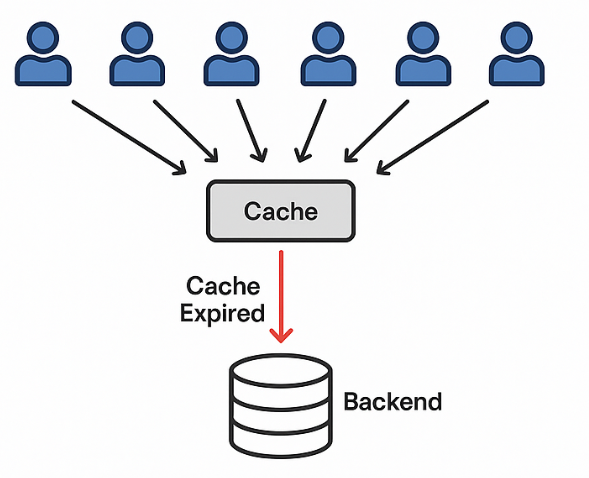
[요청 1] 캐시 없음 → DB 조회
[요청 2] 캐시 없음 → DB 조회
[요청 3] 캐시 없음 → DB 조회
...👉 원래는 캐시 1번만 갱신하면 되는데, DB를 N번 조회
2️⃣ 서버 재시작 / Redis Flush
- Redis 재시작
- FLUSHALL
- 배포 과정에서 캐시 초기화
👉 모든 캐시 키가 동시에 사라짐 → DB 부하 폭증
❗ 왜 문제가 될까?
캐시 스탬피드는 단순히 “느려지는 문제”가 아니다.
🚨 주요 위험 요소
- DB CPU / Connection Pool 고갈
- 전체 API 응답 지연
- 연쇄 장애 (Timeout → 재시도 → 더 큰 부하)
- 장애 복구 후에도 트래픽 폭주 지속
특히 트래픽이 많은 서비스일수록
👉 “캐시가 오히려 장애의 트리거가 되는 상황” 이 발생한다.
4️⃣ 캐시 스탬피드 해결 전략 분류
해결 방법은 크게 4가지 관점으로 나눌 수 있다.
| 관점 | 핵심 질문 |
| 만료 분산 | 동시에 만료되지 않게 할 수 없을까? |
| 재생성 제어 | 누가 캐시를 다시 만들 것인가? |
| 사용자 영향 최소화 | 캐시가 없을 때도 응답할 수 없을까? |
| 사전 대응 | 캐시가 비기 전에 미리 준비할 수 없을까? |
5️⃣ 해결 방법 ① 지터(Jitter) — 만료 분산
🔹 개념
TTL에 랜덤 값을 추가하여
캐시 만료 시점을 분산시키는 방법
TTL = 60초 + random(0~10초)✅ 장점
- 구현 가장 쉬움
- 모든 캐시 시스템에서 사용 가능
- 대량 동시 만료 방지
❌ 한계
- 인기 키 1개에 트래픽 집중 시 효과 제한
6️⃣ 해결 방법 ② 분산 락(Distributed Lock) — 재생성 제어
🔹 개념
캐시가 없을 때
👉 단 한 요청만 DB를 조회하도록 락 적용
캐시 없음
→ 락 획득 성공자만 DB 조회
→ 캐시 저장
→ 나머지는 대기 / 재시도구현 방식
- Redis SETNX
- Lua Script
- Redisson
✅ 장점
- DB 요청 1회로 제한
- 인기 키에 매우 효과적
❌ 단점
- 구현 복잡
- 타임아웃/데드락 고려 필요
👉 “핵심 인기 키”에만 선택 적용
7️⃣ 해결 방법 ③ 선계산(Precompute / Warm-up) — 사전 대응
🔹 개념
캐시가 비기 전에
👉 미리 계산해서 채워두는 방식
사용 예
- 메인 페이지
- 랭킹
- 통계 데이터
- 추천 결과
스케줄러 / 배치 / 이벤트 기반
→ 캐시 갱신✅ 장점
- 사용자 요청과 분리
- DB 부하 예측 가능
❌ 단점
- 모든 키에 적용 불가
- 트래픽 패턴을 알아야 함
8️⃣ 해결 방법 ④ Soft TTL — 사용자 영향 최소화
🔹 개념
- 캐시는 논리적으로 만료
- 기존 값은 바로 삭제하지 않음
- 백그라운드에서 갱신
만료됨
→ stale 데이터 반환
→ 비동기 캐시 갱신✅ 장점
- 사용자 응답 지연 없음
- 스탬피드 발생 거의 없음
❌ 단점
- 오래된 데이터 제공 가능
- 구현 난이도 높음
9️⃣ 해결 방법 ⑤ PER (Probabilistic Early Refresh) — 고급 기법
🔹 개념
TTL이 남아 있어도
👉 확률적으로 캐시를 조기 갱신
TTL이 적고
요청 빈도가 높을수록
→ 갱신 확률 증가✅ 장점
- 락 없이도 스탬피드 방지
- 자연스러운 분산
❌ 단점
- 구현 복잡
- 일반 CRUD 서비스엔 과함
👉 대규모 트래픽 / CDN / 추천 시스템에서 사용
✅ 현실적인 Best Practice
1. 모든 캐시에 TTL Jitter 적용
2. 트래픽 집중 키에만 분산 락 적용
3. 메인/랭킹 데이터는 선계산
4. 초대규모 서비스라면 PER 또는 Soft TTL 고려📊 해결 방법 한눈에 정리
| 방법 | 목적 | 난이도 | 비고 |
| 지터 | 만료 분산 | ⭐ | 필수 |
| 분산 락 | 재생성 제어 | ⭐⭐⭐ | 인기 키 |
| 선계산 | 사전 대응 | ⭐⭐ | 예측 가능 데이터 |
| Soft TTL | UX 보호 | ⭐⭐⭐⭐ | stale 허용 |
| PER | 고급 분산 | ⭐⭐⭐⭐ | 초대규모 |
✍️ 마무리
캐시는 성능을 높이기 위한 도구지만,
스탬피드를 고려하지 않으면 가장 위험한 지점이 된다.하나의 해결책이 아니라,
트래픽 특성에 맞는 조합이 핵심이다.
LIST
'BE > DB' 카테고리의 다른 글
| [DB] Redis (0) | 2025.12.07 |
|---|---|
| [DB] 데이터 무결성(Integrity)의 종류와 제약조건 정리 (0) | 2025.11.02 |
| [DB] 트랜잭션(Transaction)과 ACID 특성 정리 (0) | 2025.10.29 |
| [DB] 벡터 데이터베이스(Vector DB) (0) | 2025.09.22 |
| [SQL] 명령어 분류 - DDL / DML / DCL / TCL (0) | 2025.09.22 |